
















Proxies for DuckDuckGo: A Practical Guide to Search-Data Collection
DuckDuckGo rarely gets the first slot when teams decide where to track rankings or pull SERP data, since Google and Bing usually take the budget. That is an oversight worth fixing. A privacy-minded audience, a results page assembled differently from Google’s, and a query stream that doubles as a window into Bing’s index all make DuckDuckGo a useful data source for SEO and market research. The practical obstacle is that collecting that data at any real volume means putting a proxy for DuckDuckGo in front of your requests. This guide explains why proxies are needed, which type fits the job, how to localize results by market, and how to build a collection workflow that holds up past the first few hundred queries.
Why DuckDuckGo data is worth collecting
The scale is smaller than Google’s, but it is not a rounding error. Independent trackers and analytics roundups put DuckDuckGo at roughly 100 million searches a day, about 3 billion a month, with a global share in the 0.6 to 0.9 percent range and a stronger 1.8 to 2.1 percent in the United States, where it ranks as the second most-used mobile search engine. DuckDuckGo stopped publishing exact traffic in 2022, so treat any precise figure as an estimate rather than an audited number.

Two things make that traffic interesting for data teams. First, the audience skews privacy-conscious and US-heavy: roughly half of all queries originate in the United States, followed by Germany, the UK, and India, and the 25 to 34 group is the largest segment. If your product or content targets those users, DuckDuckGo visibility matters more than the global percentage suggests. Second, because DuckDuckGo’s traditional web results come largely from Bing, monitoring the DuckDuckGo SERP gives you a cheap, secondary read on how Bing’s index ranks your pages, which is useful when you cannot or do not want to scrape Bing directly.
Typical jobs that justify a DuckDuckGo data pipeline:
- Rank tracking for a privacy-first or US-heavy audience.
- SERP feature monitoring, including instant answers, the AI summary, and which sources get cited.
- Ad verification, confirming that sponsored placements show up correctly per market. DuckDuckGo’s average cost-per-click is reported near $0.41, far below Google’s, so it is a real channel for some advertisers.
- Market and competitor research, where a non-personalized results set is an advantage: DuckDuckGo does not tailor results to a profile, so two clean requests for the same query and region should return the same ranking.
How DuckDuckGo serves results
You cannot build a stable scraper without understanding what you are scraping. DuckDuckGo is not a single index. It blends results from “over 400 sources,” with the bulk of the standard ten blue links coming from Bing, supplemented by its own crawler (DuckDuckBot), instant-answer providers such as Wikipedia, Wolfram Alpha and Apple Maps, and, since 2023, an AI answer layer that draws on models from OpenAI and Anthropic. The Bing dependency is not theoretical: during a Bing API outage in 2024, DuckDuckGo briefly stopped returning results altogether.
For collection purposes, the most important detail is that DuckDuckGo exposes more than one front door. The main duckduckgo.com interface is JavaScript-heavy and gates pagination behind a dynamic vqd token, which makes it the hardest to script. DuckDuckGo also maintains stripped-down HTML and “lite” versions, originally built for browsers without JavaScript, and those are far friendlier to a server-side parser.
| Endpoint | What it returns | JavaScript | Best for |
| duckduckgo.com/ | Full SERP: organic results, instant answers, ads, AI summary | Yes (vqd token + JS) | Capturing rich features and ad units |
| html.duckduckgo.com/html/ | Static HTML organic results | No | Standard server-side parsing |
| lite.duckduckgo.com/lite/ | Minimal, fastest-loading results | No | High-volume rank checks |
DuckDuckBot is not the same as scraping DuckDuckGo
This trips people up constantly, so it is worth stating plainly. DuckDuckBot is DuckDuckGo’s own crawler visiting your site; you control it through robots.txt the same way you would Googlebot, and it is widely reported as one of the more compliant, low-aggression crawlers on the web. Scraping DuckDuckGo is the opposite: you send automated requests to DuckDuckGo’s SERP to collect data. The two have nothing to do with each other operationally, and only the second one needs a proxy. If your goal is simply to make sure DuckDuckGo indexes your pages, the lever that matters most is being indexed in Bing, not anything proxy-related.
Why you need proxies for DuckDuckGo
DuckDuckGo’s results are anonymous by design, with no account, no profile, and no personalized ranking. That removes one problem, since you never need to manage logged-in sessions, but it leaves the one that actually stops automated collection: rate limiting tied to your IP address.
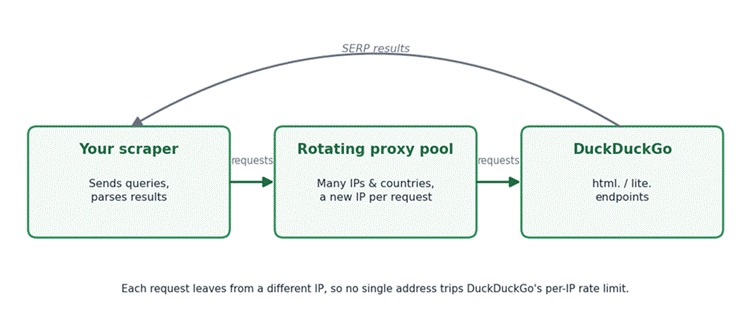
DuckDuckGo actively pushes back on automated traffic to its HTML endpoints. In practice you will see 202, 403, and similar responses once a single address sends too many requests too quickly. There is no officially published threshold, and the community consensus, reflected in the popular duckduckgo-search (now ddgs) Python library, is to rotate proxies, stay well under about 30 requests per minute per IP, and space requests with randomized delays. Independent scraping write-ups rate DuckDuckGo as only moderate difficulty, with rate limiting as the primary defense and light TLS-fingerprint checks layered on top.
The fix is straightforward in principle. You spread the workload across many IP addresses so that no single one trips the per-IP limit, and you rotate addresses as you go. This is not about disguising who you are. It is about staying inside the request budget DuckDuckGo tolerates and not degrading the service for anyone else. A handful of queries from one machine is fine without a proxy; a rank-tracking job covering thousands of keyword-region pairs is not.
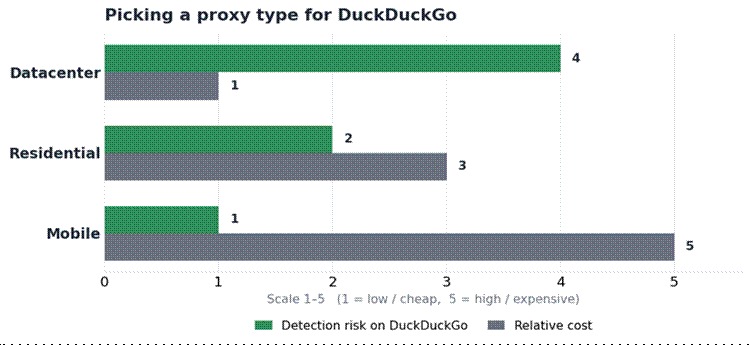
Choosing the right proxy type
Not every proxy behaves the same against DuckDuckGo’s rate limiting. The decision usually comes down to detection risk versus cost and speed, so understanding how to use a proxy with DuckDuckGo can help you choose the right option for your workload.
| Proxy type | Detection risk on DuckDuckGo | Relative cost | Speed | Best fit |
| Datacenter | Higher; flagged faster under sustained load | Lowest | Fastest | Low-volume, non-time-sensitive monitoring |
| Residential (rotating) | Low | Medium | Medium | Sustained, large-scale SERP collection |
| Mobile | Lowest | Highest | Medium | Hardest jobs, or when residential IPs get flagged |
A few protocol notes affect implementation more than people expect. IPv4 is the safe default. IPv6 is cheaper but more likely to be treated as suspect by some endpoints, so test it on a small batch before committing a large job to it. On the transport layer, HTTP(S) proxies cover most scraping stacks, but some toolchains route cleanly only over SOCKS5, so it pays to confirm both are available before you wire everything together. Providers that expose datacenter, residential and mobile IPv4 from a single account, proxys.io among them, make this easier in practice, because you can start a job on inexpensive datacenter addresses for light monitoring and move the same job to residential or mobile IPs the moment DuckDuckGo starts returning 202s under load.
Localizing results by market
DuckDuckGo lets you pin the SERP to a market with the kl region parameter: us-en for the United States, uk-en for the United Kingdom, de-de for Germany, fr-fr for France, wt-wt for worldwide, and so on. For rank tracking and ad verification, this is the parameter that lets you see the page roughly as a searcher in that market would.
| Region code (kl) | Market |
| us-en | United States (English) |
| uk-en | United Kingdom |
| de-de | Germany |
| fr-fr | France |
| ru-ru | Russia |
| wt-wt | No region / worldwide |
The subtle part is consistency. The kl value sets the locale of the results, but the IP address you connect from still carries a geographic signal, and a mismatch between the two can introduce noise into your sample, which is exactly what you do not want when the point is an accurate, repeatable read on a specific market. The clean approach is to align your exit IP’s country with the region code you send, so the request is internally coherent. Coverage breadth is the practical limit here: a pool that lists exit locations across the US, UK, Germany, France, Spain, Poland, the Netherlands, Canada, Brazil and India (the country list proxys.io publishes is a representative example) is usually enough to pair an IP with each region code an SEO team tracks. Where a country is not offered, the more honest option is to drop that locale from the run rather than send a mismatched IP that quietly skews the data.
A practical collection workflow
Here is a workflow that holds up well for medium-scale DuckDuckGo collection. It assumes you are using one of the no-JavaScript endpoints, which removes most of the fragility.
1. Pick the endpoint to match the data you need. Use lite.duckduckgo.com for raw rankings at volume, html.duckduckgo.com when you want a bit more structure, and the main site only if you specifically need ads, instant answers, or the AI summary.
2. Set the region with kl, and align the proxy’s exit country to it.
3. Rotate the proxy on every request, or at least on every new job, and cap concurrency so you stay under the roughly 30-requests-per-minute-per-IP guideline.
4. Add randomized delays between requests rather than a fixed interval, since a constant cadence is itself a detectable pattern.
5. Handle pagination carefully. An initial request returns up to about 35 organic results; using an offset can return up to about 50, but higher offsets also raise the odds of duplicated or variable result counts, so de-duplicate on the way in. On the main site, pagination depends on the vqd token; if it expires, pagination simply fails, so re-fetch the first page to pull a fresh token and retry.
6. Back off on errors. Treat 202 and 403 as a signal to pause, rotate to a new IP, and slow down, not to retry harder.
A minimal illustration of the request layer, with a rotating proxy and a region code:
| import random, time, requests PROXIES = [ … ] # your rotating pool, e.g. http://user:pass@host:port def fetch(query, kl=”us-en”): proxy = random.choice(PROXIES) r = requests.get( “https://html.duckduckgo.com/html/”, params={“q”: query, “kl”: kl}, proxies={“http”: proxy, “https”: proxy}, headers={“User-Agent”: “Mozilla/5.0 … Chrome/120 Safari/537.36”}, timeout=30, ) if r.status_code in (202, 403): time.sleep(random.uniform(5, 12)) # back off, then rotate next call return None return r.text # hand off to BeautifulSoup for parsing |
Parsing itself is undramatic. DuckDuckGo’s lite and HTML pages are static, so a standard request plus BeautifulSoup pass extracts titles, links, and snippets without browser automation. Reserve headless browsers for the cases where you genuinely need JavaScript-rendered features.
Limitations, trade-offs, and responsible use
A proxy solves the IP rate-limit problem. It does not make scraping consequence-free, and an honest guide has to say so.
It sits in a legal and policy gray area. Collecting publicly available data is lawful in most jurisdictions, but DuckDuckGo’s terms prohibit automated, non-personal use of the site, and the company states plainly that it works to block scrapers. Respect robots.txt, keep request rates modest, collect only public data, and get legal advice if your use case is commercial or large-scale. Restraint here is not just compliance theater. Overloading the endpoints degrades the service for real users, which is the behavior the rate limiting exists to prevent.
Custom scrapers are brittle. When DuckDuckGo changes its HTML structure, a hand-rolled parser breaks, and the vqd token mechanics on the main site change periodically. The upside of owning the scraper is that you can patch it on your own schedule. The upside of a library like ddgs is that someone else maintains it, but then you wait for their fix when it breaks. There is no free lunch, only a choice about who carries the maintenance burden.
There is no official SERP API. DuckDuckGo offers an Instant Answer API, but it returns instant answers, not the full web results most teams want, and commercial use requires identifying your app, attributing results, and getting email approval first. (DuckDuckGo is, to its credit, known to actually answer those emails.) For full SERP data you are either scraping the HTML endpoints yourself or paying a managed SERP-API vendor that does the scraping and proxy rotation for you. That build-versus-buy call hinges on volume, in-house engineering capacity, and how much you value control over reliability.
The Bing dependency is a standing risk. Because so much of DuckDuckGo’s result set comes from Bing, upstream changes ripple downward. Microsoft’s 2025 moves around its search APIs are a reminder that the data source you are monitoring is not fully in DuckDuckGo’s hands, and therefore not fully in yours.
A few lessons that tend to repeat across projects: start slower than you think you need to and ramp up; rotate IPs and vary timing, because rate limiting keys on patterns and not just volume; align proxy geography with the kl region or accept noisier data; and de-duplicate aggressively once you page past the first set of results.
FAQ
Do I need a proxy to scrape DuckDuckGo?
For a few one-off queries, no. For anything consistent or at scale, yes: rate limiting is tied to your IP, and rotating proxies keep you inside the request budget DuckDuckGo tolerates.
How many requests per minute per IP is safe?
DuckDuckGo publishes no official limit. A common rule of thumb is under roughly 30 per minute per IP, with randomized delays, backing off immediately on 202 or 403 responses.
Which proxy type works best for DuckDuckGo?
Rotating residential proxies are the reliable default for sustained collection. Mobile IPs are the most resilient but the priciest. Datacenter addresses suit low-volume monitoring.
Does DuckDuckGo have an official API for search results?
Not for full web results. The Instant Answer API covers instant answers only. Full SERP data comes from scraping the HTML or lite endpoints, or from a third-party SERP API.
Can I get country-specific DuckDuckGo results?
Yes. The kl parameter sets the market (for example us-en, uk-en, de-de). For accurate results, align the exit country of your proxy with the region code you send.





