










How to Improve Your Google PageSpeed Insights Score: Best Practices in 2022
When was the last time you abandoned a website because its page was taking too long to load? You are not alone in doing so! In fact, most internet users find slow-loading pages to be a huge annoyance. In this article, we will explain best practices for improving your Google PageSpeed Insights Score in 2022. Keep reading!
According to Pingdom, 38 percent of website users bounce if a site takes more than five seconds to load. Yet, a survey by Unbounce revealed that only 15 percent of sites have acceptable page speed!
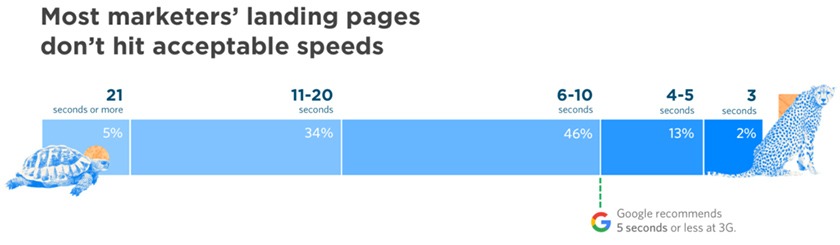
This is quite a damaging statistic when you consider the sheer importance of page speed in ensuring conversion.

The question arises, what exactly is the right page speed? The answer to this keeps changing. While there was a time when a page speed of seconds was acceptable, now companies strive to achieve a load time of fewer than three seconds.
A great way to stay abreast about the standard page speed is by making use of Google PageSpeed Insights. This tool allows you to gauge your page’s speed and the score it gives you helps you identify whether you need to improve your efforts or not. Generally, a 90 plus score is considered acceptable.
In case you don’t achieve this score, here are some of the best practices you can implement to improve the PageSpeed insights score.
How to Improve Your Google PageSpeed Insights Score: Best Practices in 2022
Google Pagespeed insights become more and more important after the major Web Vitals algorithm update. Web Vitals is an initiative by Google to provide unified guidance for quality signals that are essential to delivering a great user experience on the web. It was one of the biggest algorithm updates in Google’s history. So here, we tried to explain effective strategies for improving your page speed insights score.
1. Compress Your Images
In today’s world, aesthetics matter a lot. This might tempt some of you to place high-quality images on your website. While there is nothing wrong with this step, and certainly the quality of your images matter, don’t confuse quality pictures with high-resolution images.
You can still achieve excellent quality without using the highest resolution available. In fact, a great way to improve website speed is to compress your images. It turns out you can use compression tools to reduce image size by up to 50 percent without compromising its quality.
For instance, for those who have a WordPress website, a plugin called WP Smush Image Compression and Optimization can be a handy tool, especially considering that the plugin is free to use!
Additionally, in case your website is not made on WordPress, you can use various other plugins available. While Crush.pics is an excellent tool for Shopify tools, Compress JPEG and Optimizilla are worthy options.
2. Eliminate Unnecessary Redirects
Another big annoyance for a website user, apart from slow-loading pages, is websites that keep on redirecting to other pages when you click on the landing page link.
It turns out that both the annoyances are related! The more redirects your pages has, the higher will be the page’s load speed. You can easily kill two birds with one stone by eliminating unnecessary redirects from your page.
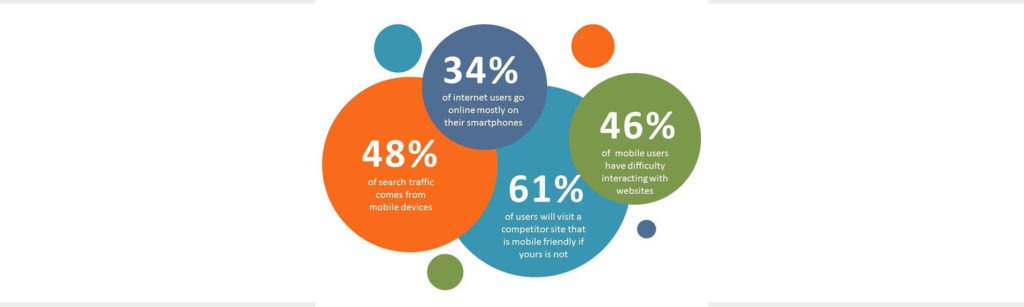
For this purpose, you need a responsive design. According to Infront, over 77 percent of adults own a smartphone, and 60 percent of people access websites through a phone. A responsive design allows that a website remains accessible, regardless of what device the user is viewing it on:
According to Google, pages with a low PageSpeed Insights Score tend to have a certain redirect pattern. Here are some of the patterns that may be exhibited:
- xyz.com -> www.xyz.com -> m.xyz.com. Such websites offer a very slow experience on mobile devices.
- xyz.com -> m.xyz.com/home. This offers a considerably slower experience than a responsive design.
Are you wondering what a responsive web design will seem like? Well, its URL (in this case, xyz.com) will load the landing page, regardless of what device it is accessed on, without any redirects. This is what you should aim for.
3. Remove All Render-Blocking Resources
Another sure-shot way of increasing page speed score is to remove any render-blocking resources from your website. Such resources also play a role in reducing page speed.
Unless you are a computer geek, the chances are that you have zero ideas about what we mean by render-blocking resources. Don’t worry; we had to learn about it too!
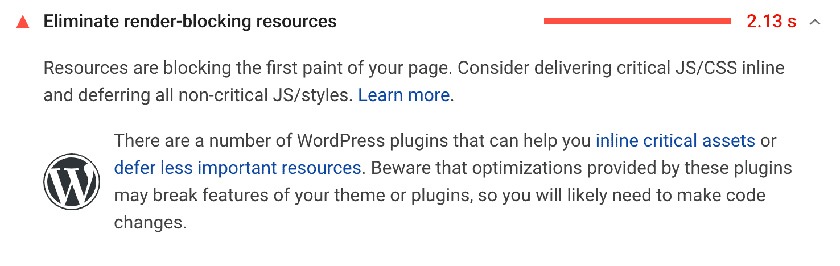
Basically, such resources refer to CSS and JavaScript scripts that act as obstacles to quick page loading. This is because every visitor’s browser is given the task of first downloading these scripts and then processing them before the full page can be displayed.
Having such resources placed above the fold section of the page can be detrimental to the website. Google itself offers a solution for this issue. This includes:
- Using plugins like Autoptimize (if your website is small) to incorporate your CSS or JavaScript into HTML files. This method is only for small websites since it will actually be counterproductive for larger websites with a plethora of scripts.
- Deferring your JavaScript allows your JavaScript file to be downloaded during the HTML parsing process and be executed once the parsing process has been completed. It also allows scripts to load in terms of appearance order on a given page.
This is quite a technical field; hence you will need a dedicated guide to combat this.
4. Improve Your Perceived Performance
A MOVR report shed light on peculiar consumer behavior. Over 11 percent of mobile phone users begin scrolling through a website, top-down, within mere four seconds of the page loading. And even if the entire page hasn’t loaded, 9 percent still scroll down.
This means you don’t necessarily have to ensure that your entire page loads quickly. Instead, you need to optimize its perceived performance. Do so by prioritizing the quick loading of above-the-fold content. Doing so will automatically boost your page speed score as well.

What is perceived performance?
It refers to the perception that users have about the quickness of your website’s loading time. This view can actually be different from the actual load time of your website! For instance, websites that load top-down may overall load at five seconds but have a perceived performance of three seconds.
Allow your above-the-fold core elements to load before any ads and third-party widgets. Make sure that content that gives structure to your site load before the aesthetic elements. By the time users process the information given, the rest of your website can load.
5. Use Browser Caching
According to Neil Patel, another tool that can help boost your Google PageSpeed Insight Score is browser caching. Compared to other practices mentioned in this guide, this one is very straightforward and doesn’t require much effort.
Generally, a page tends to take a long time to load because it is fetching the required resources. For instance, each time a website is revisited, it needs to fetch and load each image and other page elements. Then, it has to deal with all the heavy HTML and coding.
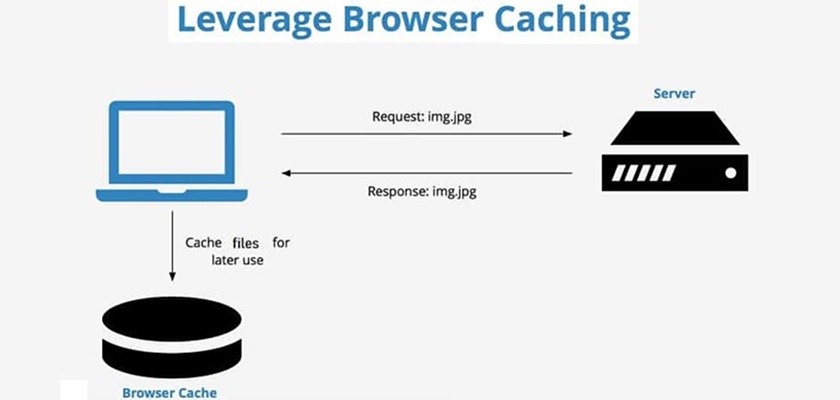
As you can observe, this task is quite repetitive. Certainly, any way to reduce the redundancy of efforts can improve the website’s performance, right? This is where browser caching comes in.
It allows browsers to remember pages and resources that have been previously loaded. This means that it doesn’t need to reload it all from scratch.
Additionally, this allows website visitors who begin their journey on the landing page to not have to wait for repetitive data, like logos and footers, to reload when they click on other pages.
Contrary to popular belief, you don’t need to know coding to use this tactic. Instead, there are tools available for it. For WordPress, you can use W3 Total Cache.
So, how do you implement it? Thankfully, there’s a plugin for it. You don’t need to be a coding expert to do this.
6. Use AMP
Accelerated Mobile Pages is an open-source solution used by Google to allow mobile pages to load faster. It does so by eliminating unnecessary content on a website to ensure that it loads instantly. You might have seen the initials reflected on various Google search results.
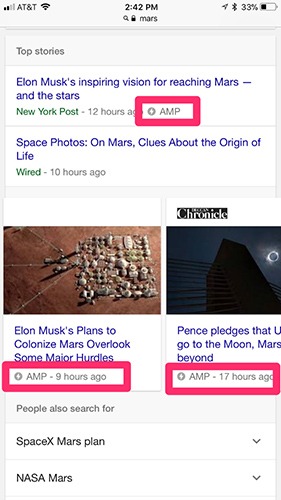
The platform delivers smooth navigation for mobile users after removing clunky features which are incompatible with an ideal mobile experience.
The simplified version of the website allows users to scroll different stories and content on a site without leaving a given page and redirecting to another one. For instance, you can easily swipe right or left to read other articles, which will pop up instantly, with very minimal formatting.
A case study reported by Neil Patel reveals that Gizmodo improved its load speed by three times using the AMP feature. You can easily implement and benefit from it too.
Ending Remarks
There are numerous ways for you to boost your Google PageSpeed Insight score. We have mentioned the ones that are being heavily implemented in 2021, with a focus on those that are easier to follow for both novices and experts.
Don’t let a slow page speed ruin your hard work and efforts. And don’t underestimate its power on your website bounce rate, either. Use Google PageSpeed Insight to see where your website lies currently.
Good luck!